一次SQL优化记录
Oct182012
在给客户巡检时,发现一个用PL/SQL Developer执行的效率低下SQL,如下:

SQL语句如下:
UPDATE TS_R_ORDER_DAY_004_TEMP A
SET USER_TAG =
(select z.USER_TAG
from (SELECT USER_TAG,
ORDER_ID,
ROW_NUMBER() OVER(PARTITION BY ORDER_ID ORDER BY CLCT_DAY DESC) RN
FROM TS_UH_ORDER_GOODS) z
where A.ORDER_ID = z.ORDER_ID
and rn = 1)
WHERE EXISTS
(SELECT 1 FROM TS_UH_ORDER_GOODS X WHERE A.ORDER_ID = X.ORDER_ID)
SQL执行计划如下:
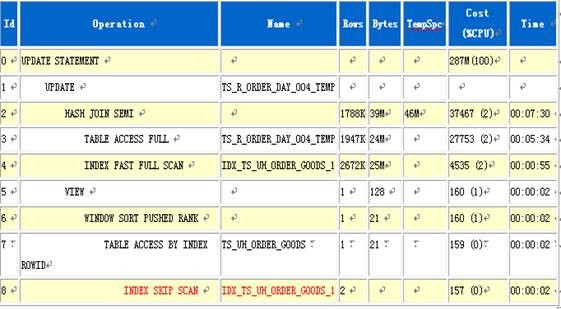
通过执行计划可以看到,对Cost影响较大部分为IDX_TS_UH_ORDER_GOODS_1表的索引跳扫,Cost值157,虽然只有157,但是对走索引来说,157的Cost已经很大了,如果正常索引扫,这个值会小很多,而且INDEX SKIP SCAN的结果和HASH JOIN SEMI循环,导致总Cost达到287M(100),如果能将索引跳扫的Cost从157降下来,INDEX SKIP SCAN的结果和HASH JOIN SEMI循环的总Cost就会成几何下将,这个SQL优化重点也是使索引跳扫改成正常索引扫,猜测产生索引跳扫的原因可能是IDX_TS_UH_ORDER_GOODS_1表上存在复合索引,而该表的ORDER_ID列不是复合索引的第一列,解决方法:在IDX_TS_UH_ORDER_GOODS_1表的ORDER_ID列上单独建立索引。
但是无法接触客户的生产环境,只能给客户建议,至于客户会不会按照建议调试就是未知数了,而且这个SQL只执行了一次,也许这个SQL的运行时间客户是可以接受的,期待客户反馈。