监听响应异常故障解决
昨天帮一个汽车金融公司解决了一个用户登录异常缓慢的故障,用户通过应用程序访问数据库异常缓慢,通过PLSQL Developer登录也需要20多秒才能登录。尝试通过操作系统认证的方式登录数据库没有问题。数据库版本11.2.0.1.0,操作系统红帽linux 5.8。
[oracle@xxx ~]$ sqlplus / as sysdba SQL*Plus: Release 11.2.0.1.0 Production on Fri Aug 8 15:47:24 2014 Copyright (c) 1982, 2011, Oracle. All rights reserved. Connected to: Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - Production With the Partitioning option SQL> [oracle@xxx ~]$ sqlplus user/password SQL*Plus: Release 11.2.0.1.0 Production on Fri Aug 8 15:48:54 2014 Copyright (c) 1982, 2011, Oracle. All rights reserved. Connected to: Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - Production With the Partitioning option
在服务器上直接访问数据库没有任何问题,很快就可登录。查看AWR报告也未发现异常。
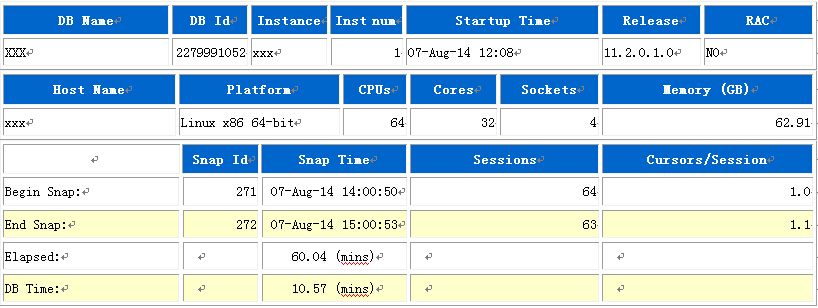
从这部分信息可以看出,数据库相当的闲,基本没有什么业务,从snap id可以看出,这个库刚创建不久,问了相关人员,他们说这是新建的库,数据刚迁过来,具体什么时候开始有这个问题的竟然没人知道,就说最近就很慢。
下面在看看,数据库的负载信息。
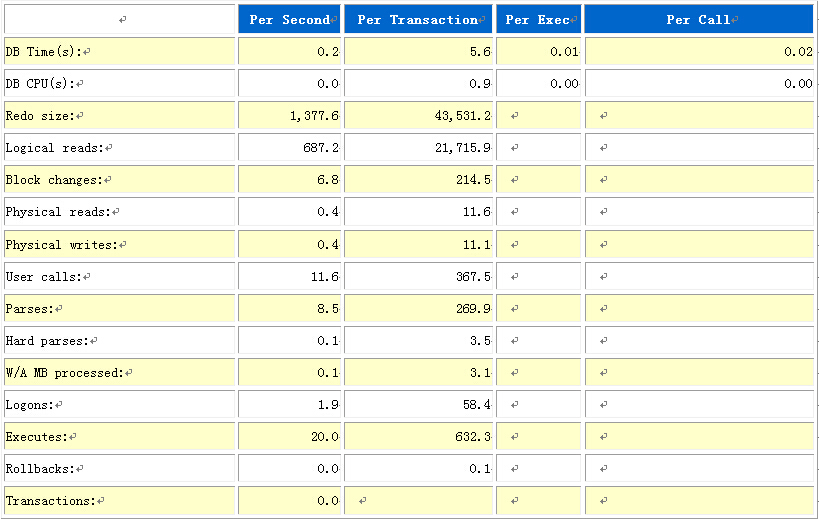
多么闲的系统啊,数据库基本没有什么负载。再看看等待事件。
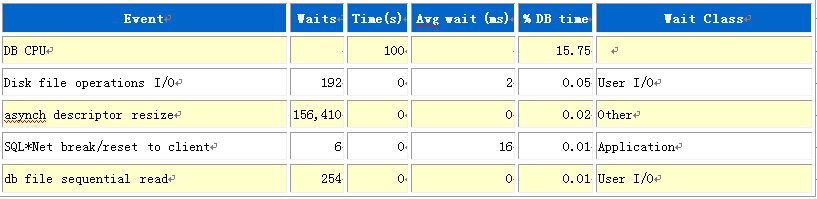
也没有发现异常的等待,看了下后台进程的等待,也没发现异常,基本可以断定,问题不是出在数据库层面。
在服务器上通过监听登录数据库,问题出现,特别慢。
[oracle@xxx ~]$ sqlplus user/password@localhost/xxx --此处卡住大约20秒 SQL*Plus: Release 11.2.0.1.0 Production on Fri Aug 8 16:04:22 2014 Copyright (c) 1982, 2011, Oracle. All rights reserved. Connected to: Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - Production With the Partitioning option SQL>
问题很明显是出在网络层面,通过ping命令发现网络很好,延迟都非常小,排除由于网络带宽不足导致登录缓慢。查看监听,发现竟然没有监听文件,监听通过默认值启动(不影响使用)。
这简单描述下监听的三要素,这要这三要素具备,监听就可以工作。这三要素分别是协议、主机名、端口号。协议默认是TCP协议,主机名默认是当前的主机,端口号默认是1521。这些数据默认值都知道了,虽然没有监听文件,监听一样可以起来并提供工作。
配置监听文件后,重新启动监听,重启监听后,如果没有配置静态注册,数据库服务不会立即之策到监听上,需要到数据库里注册,或者过两分钟,PMON进程会主动将数据库服务推送给监听器,如果配了静态注册,就不需要了。
SQL> alter system register; System Altered.
再次通过监听连接数据库,问题依旧。检查hosts文件,发现hosts文件配置的有点问题。
[root@xxx ~]# cat /etc/hosts # Do not remove the following line, or various programs # that require network functionality will fail. 127.0.0.1 xxx localhost.localdomain localhost 10.0.11.1 localhost6.localdomain6 localhost6
修改hosts文件,讲IP地址后面改成主机名。
[root@xxx ~]# cat /etc/hosts # Do not remove the following line, or various programs # that require network functionality will fail. 127.0.0.1 xxx localhost.localdomain localhost #10.0.11.1 localhost6.localdomain6 localhost6 10.0.11.1 xxx
通过监听连接数据库,问题没有解决,还是很慢,设置监听的trace,通过监控监听,看看到底是哪慢。
[oracle@xxx ~]$ lsnrctl LSNRCTL for Linux: Version 11.2.0.1.0 - Production on 08-AUG-2014 16:10:06 Copyright (c) 1991, 2011, Oracle. All rights reserved. Welcome to LSNRCTL, type "help" for information. LSNRCTL> set trc_level support Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=xxx)(PORT=1521))) LISTENER parameter "trc_level" set to support The command completed successfully
通过status命令查看当前使用的trace文件。
LSNRCTL> status Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=xxx)(PORT=1521))) STATUS of the LISTENER ------------------------ Alias LISTENER Version TNSLSNR for Linux: Version 11.2.0.1.0 - Production Start Date 09-AUG-2014 16:10:30 Uptime 0 days 0 hr. 1 min. 19 sec Trace Level support Security ON: Local OS Authentication SNMP OFF Listener Parameter File /u01/app/oracle/product/11.2.0/dbhome_1/network/admin/listener.ora Listener Log File /u01/app/oracle/diag/tnslsnr/xxx/listener/alert/log.xml Listener Trace File /u01/app/oracle/diag/tnslsnr/xxx/listener/trace/ora_6273_3043251904.trc Listening Endpoints Summary... (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=xxx)(PORT=1521))) (DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(KEY=EXTPROC1521))) Services Summary... Service "xxx" has 1 instance(s). Instance "xxx", status READY, has 1 handler(s) for this service... The command completed successfully
通过在另一个窗口监控这个文件,在其他窗口通过监听登录数据库,发现卡住的时候的监听日志信息如下:
2014-08-07 16:15:47.197635 : nsevfnt:cxd: 0xff4d2f8 stage 0: NS events set: 2014-08-07 16:15:47.197656 : ntpctl:entry 2014-08-07 16:15:47.197681 : sntpcall:result string is NTP0 6879 2014-08-07 16:15:47.197708 : sntpcall:exit 2014-08-07 16:15:47.197728 : ntpctl:exit 2014-08-07 16:15:47.197767 : nttaddr2bnd:entry 2014-08-07 16:15:47.197789 : snlinGetNameInfo:entry 2014-08-07 16:15:47.197814 : snlinGetNameInfo:exit 2014-08-07 16:15:47.197835 : nttaddr2bnd:Resolved to 10.0.11.1 2014-08-07 16:15:47.197860 : nttaddr2bnd:exit 2014-08-07 16:15:47.197887 : nsbequeath_stg2:doing connect handshake... 2014-08-07 16:15:47.197909 : nsbequeath:doing connect handshake... 2014-08-07 16:15:47.197930 : ntpwr:entry 2014-08-07 16:15:47.197959 : ntpwr:exit 2014-08-07 16:15:47.197983 : ntpwr:entry 2014-08-07 16:15:47.198011 : ntpwr:exit 2014-08-07 16:15:47.198032 : ntpwr:entry 2014-08-07 16:15:47.198056 : ntpwr:exit 2014-08-07 16:15:47.198077 : ntprd:entry 2014-08-07 16:16:07.199138 : ntprd:exit 2014-08-07 16:16:07.199239 : ntprd:entry 2014-08-07 16:16:07.199469 : ntprd:exit
当sqlplus卡住的时候,监听日志就卡在这里了,看到的都是ntp相关的信息,我首先想到的是是不是由于ntp服务器导致的呢?好像解释不通,不过他们还真配置了NTP服务,停掉NTP服务后,问题还是没有解决。思路再回到刚才的网络上,这个现象通常都和解析有关,那么都改好了hosts解析了,为什么还这么慢呢?难道是没有使用hosts解析?检查服务器是否配置了DNS。
[root@xxx ~]# cat /etc/resolv.conf nameserver 10.254.10.18 nameserver 10.0.1.73
可见,服务器上配置了两个DNS,这样,在访问数据库的时候,就不会优先使用hosts文件进行解析,由于时间有限,我并没有检查是DNS的IP地址不通还是网络延迟较大还是这个DNS解析不了这个主机,才会导致的问题,既然已经猜到是DNS导致的问题,那么就禁掉这两个DNS,让服务器使用hosts文件去解析。
[root@xxx ~]# cat /etc/resolv.conf #nameserver 10.254.10.18 #nameserver 10.0.1.73
禁掉DNS后,在主机上通过监听登录数据库并没有经历漫长的等待,在其他客户机上访问数据库都很正常,应用服务器连接数据库也很正常,问题解决。