分析AWR报告发现业务问题(二)
Jul092015
在分析SIT数据库的AWR报告时,发现排在TOP20第一位的SQL存在性能问题,数据库版本11.2.0.4.0,AWR信息如下:
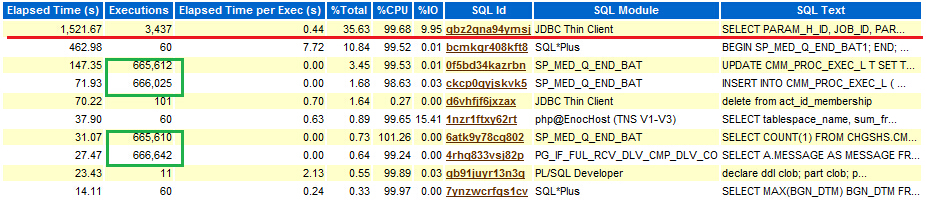
上图绿框部分的SQL也存在问题,之前已经整理,详见http://www.dbdream.com.cn/2015/07/07/%E5%88%86%E6%9E%90awr%E6%8A%A5%E5%91%8A%E5%8F%91%E7%8E%B0%E4%B8%9A%E5%8A%A1%E9%97%AE%E9%A2%98/。 上图第一条SQL的语句如下:
SELECT PARAM_H_ID, JOB_ID, PARAM_VAL, INST_DTM FROM JOB_PARAM_H where JOB_ID = (SELECT JOB_ID FROM JOB_TASK_QUARTZ where JOB_METHOD = :1) ORDER BY INST_DTM DESC
这是一条很简单的SQL,从上图也可看出这条SQL单次执行不到1秒,但是执行次数较多,在SIT环境平均一秒运行一次,上线后这块就会是个问题,下面看看该SQL的执行计划。
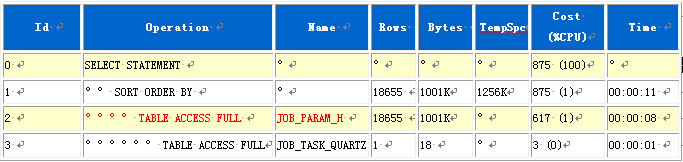
从执行计划可见,对性能影响较大的是JOB_PARAM_H表的全表扫描,看看这张表的索引情况。
CHGSHS@IVLDB > select index_name,column_name from user_ind_columns where table_name ='JOB_PARAM_H'; no rows selected
在看看JOB_PARAM_H表的数据量,是否需要创建索引。
CHGSHS@IVLDB > select count(*) from JOB_PARAM_H;
COUNT(*)
----------
11094112
CHGSHS@IVLDB > select bytes/1024/1024/1024 GB from user_segments where segment_name='JOB_PARAM_H';
GB
----------
1.09375
在JOB_ID和INST_DTM列建立复合索引。
CHGSHS@IVLDB > create index IX_JOB_PARAM_H_01 on JOB_PARAM_H (JOB_ID,INST_DTM); Index created.
再次查询,时间变为0.00秒。
CHGSHS@IVLDB > SELECT COUNT(*)
2 FROM JOB_PARAM_H
3 where JOB_ID = (SELECT JOB_ID FROM JOB_TASK_QUARTZ where JOB_METHOD = 'ordInsToJob11B')
4 ORDER BY INST_DTM DESC
5 ;
COUNT(*)
----------
14183
Elapsed: 00:00:00.00
这个JOB_METHOD = ‘ordInsToJob11B’是我随便在数据库中查询出的一个值,竟然能查出这么多的数据,而且这个SQL没有分页,那么应用程序一下查出上万条的数据干啥?查询下JOB_PARAM_H表的JOB_ID数据分布,发现JOB_ID相同的数据最少的就有8千多,也就是应用程序每次运行这个SQL,最少要查询出8千多条的记录。
CHGSHS@IVLDB > SELECT JOB_ID,COUNT(*) FROM JOB_PARAM_H GROUP BY JOB_ID;
JOB_ID COUNT(*)
---------- ----------
222 8982
224 9632
181 110295
223 9633
201 60712
164 149877
161 130966
162 144303
119 14183
163 147977
226 9634
165 136793
225 9632
221 9634
118 145537
15 rows selected.
多的竟然有十几万,应用程序一下拿那么多数据干啥?不可能前台点个按钮,返回上万的记录,都看一遍吧,问题反馈给开发人员,开发人员确认,其实他们只要第一条!!!!!