帮朋友看的一个锁表的问题
有个朋友遇到了锁表的问题,他们的应用程序在每天16点会批量修改数据,之前是串行操作的,也就是这个任务完成再开启下一个任务,这时是没有问题的,前几天开发人员将这个任务修改成并行操作了,也就是在16点所有任务都一起操作,然后就出现了锁表情况,需要很长的时候才能完成。
这很显然是程序的逻辑问题导致的锁表,我拿到了AWR、ASH、SQL report报告,下面一起来看下。先看一下AWR报告,AWR报告比较全面,包含了各方面的信息,相对来讲对于定位问题没那么直观,是DBA最常分析的报告。
下面是AWR报告的头部。
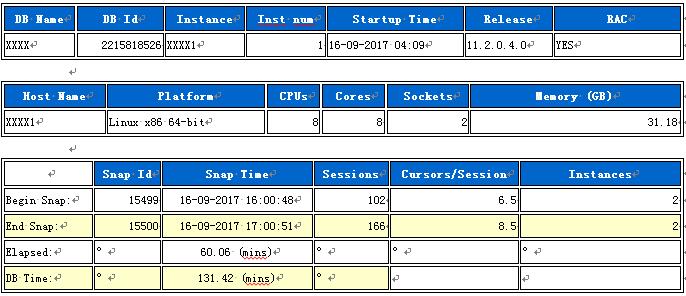
从AWR头部可以看到这个数据库是一套11.2.0.4.0版本的RAC环境,应该是2颗2核CPU的服务器,双线程一共才8核CPU,这配置已经相当低了。问了朋友,他说服务器是IBM的刀片,这样的服务器一般都是用来做应用服务器的吧,跑数据库的话配置偏低呀。
再看一下数据库的负载。
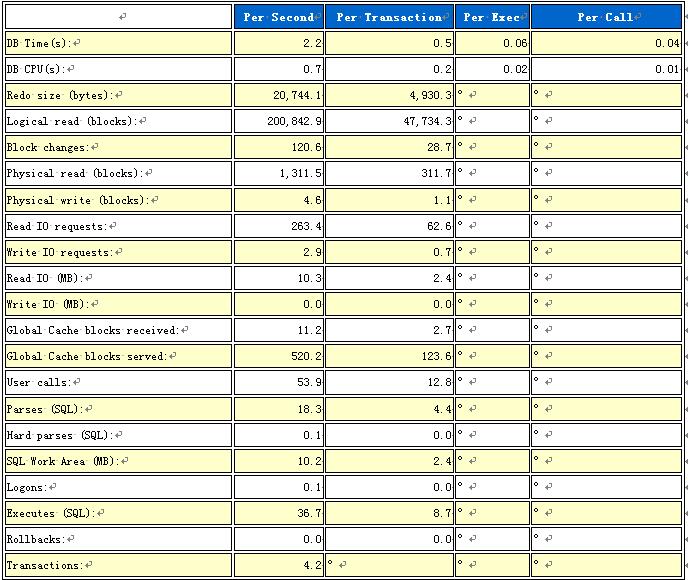
负载都很低,各项指标都还正常,怪不得服务器能抗得住。命中率指标也都正常,这里就不列出来了,下面看下TOP10等待。
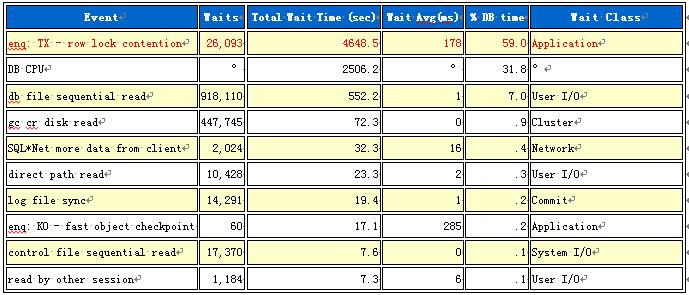
行级锁排在了第一位,一共锁了26093次,一共耗时4648.5秒,根据8核CPU换算,大约是10分钟,这和我朋友说需要十多分钟才能执行完基本是一致的。
根据运行排序的SQL部分,定位到这是个UPDATE操作。
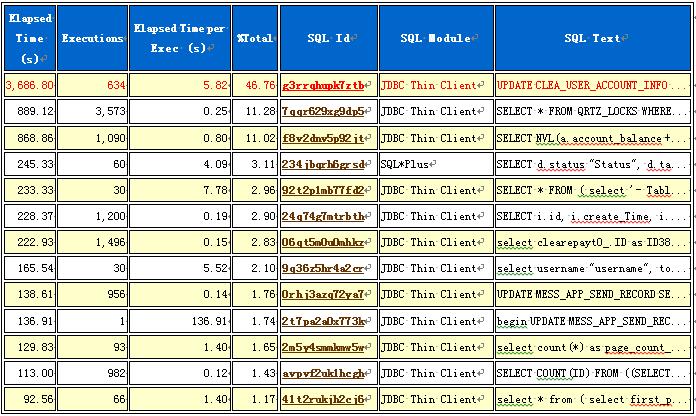
再看下行级锁等待最多的哪些对象。
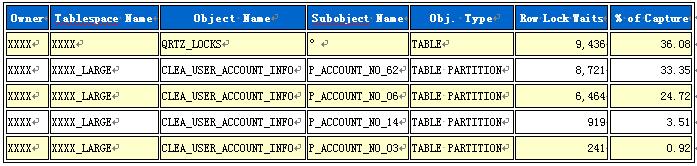
QRTZ_LOCKS表被锁了9436次,查找后发现,这竟然是for update操作。
![]()
CLEA_USER_ACCOUNT_INFO表正是上文的UPDATE操作的表,上文的SQL如下:

从上面的信息可以看出CLEA_USER_ACCOUNT_INFO是分区表,拿到表的元数据发现,ID字段是主键,这SQL是单条修改数据,速度应该会很快。
create table CLEA_USER_ACCOUNT_INFO
(
id VARCHAR2(32) not null,
account_name VARCHAR2(40),
account_no VARCHAR2(40),
… …此处省略部分代码
)
partition by hash (ACCOUNT_NO)
(
partition P_ACCOUNT_NO_01
tablespace FINSER_LARGE,
partition P_ACCOUNT_NO_02
… …此处省略部分代码
partition P_ACCOUNT_NO_66
tablespace XXXX
);
alter table CLEA_USER_ACCOUNT_INFO add constraint PK_CLEA_USER_ACCOUNT_INFO_ID primary key (ID) using index
tablespace FINSER_INDEX
下面再看看ASH报告,下面是ASH的等待事件部分,比AWR报告直观,只列出影响较大的等待事件。

从ASH的Top DB Objects部分可以看到,几乎都是那条SQL导致的行级锁。
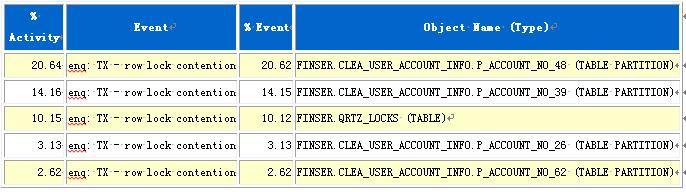
这样就定位了这条问题SQL,再看下SQL report报告,这个SQL的执行计划是什么?

这个SQL执行计划走的是主键,而且扫描的数据量非常小,这说明这条SQL应该非常快就可以执行完,这就可以排除了SQL单次执行慢导致锁的问题。再加上SQL创建语句部分,限于篇幅我删了一些,这个表存在很多VARCHAR2从40到250的字段,基本也可以排除一个数据块存放多条数据,从而导致热点块的问题。因为GC等待都很低,也可以排除是由于GC等待导致的锁表问题。还有上文的数据库负载部分,各项指标都很低,也就是说数据库并不忙,这基本也可以排除是服务器性能太差导致的处理数据慢导致的问题。
这样基本就定位是程序逻辑的问题,有可能程序设置的是修改多条之后再提交,但不管怎么说,同一时间不同会话修改同一条记录,这样的逻辑本身就有问题。
目前,朋友已经去和领导反映这个问题,具体怎么解决还没有消息。